⚗️ a Local Agent With ADK and Docker Model Runner
A French version is available here.
⛅ Using AI in the Cloud
I’m the first to admit it: I use AI models provided in the Cloud. As a user, it suits me perfectly. The models are powerful and give me good answers.
But is the scope of these models really adapted to my needs? They do the job, that’s a fact, but aren’t they a bit too general-purpose for my specific use cases?
Running models locally is not new. It was actually one of the very first requirements that emerged: trying to deploy a model on a local machine.
The apparition of Small Language Models (SLM) has offered a concrete answer to this problem, making it possible to adapt models to specific use cases and simplify their deployment.
There are now various alternatives for deploying these models. I have first heard about Ollama, as it was, if I’m right, one of the first tools to simplify this process.
If you’re interested in Small Language Models, I highly recommend Philippe Charrière’s articles available on his blog.
I took some time to make my own experience, and that’s what I’m sharing with you in this article.
🧩 My Context
For this experiment, I wanted to use my usual agent framework for its simplicity: Google’s Agent Development Kit (ADK):https://google.github.io/adk-docs/.
A Java agent can be quickly created with ADK and these lines:
public static BaseAgent initAgent() {
return LlmAgent.builder().name("trip-planner-agent")
.description("A simple trip helper with ADK")
.model(System.getProperty("gemini.model"))
.instruction("""
You are A simple Trip Planner Agent. Your goal is to give me information about one destination.
""").build();
}
🐳 Docker Model Runner
I had already tested Ollama to run models on my machine. But for this experiment, I wanted to try Docker’s solution: Docker Model Runner (DMR). This project provides new Docker commands to pull, run, and list models available on your machine.
docker model pull
docker model list
docker model run
A quick configuration is required in the Docker Desktop settings to enable this service:
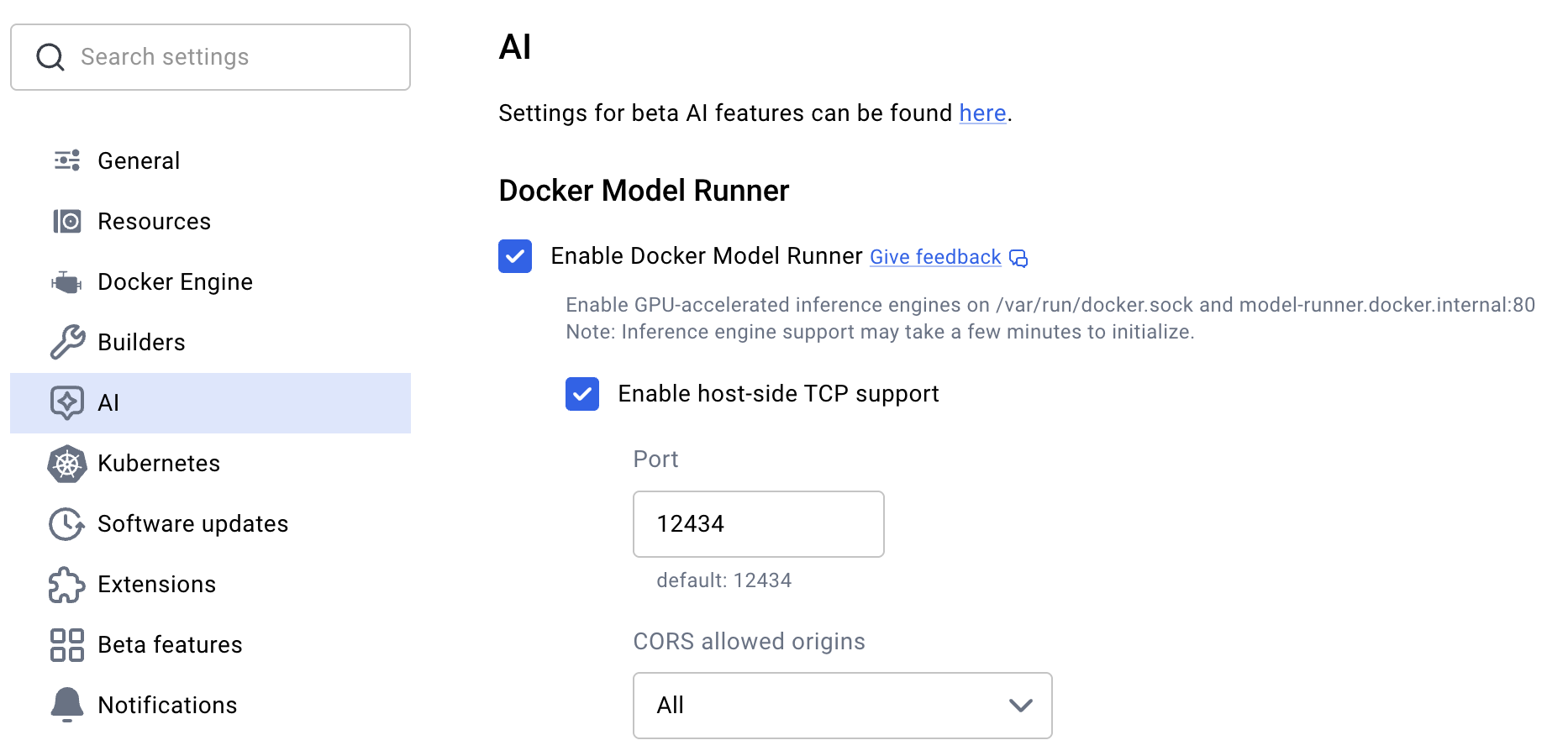
After that, DMR allows you to easily fetch a model and run it on your machine. For example, to use the “gemma3” model, simply run the following command. The model will be downloaded if you don’t already have it:
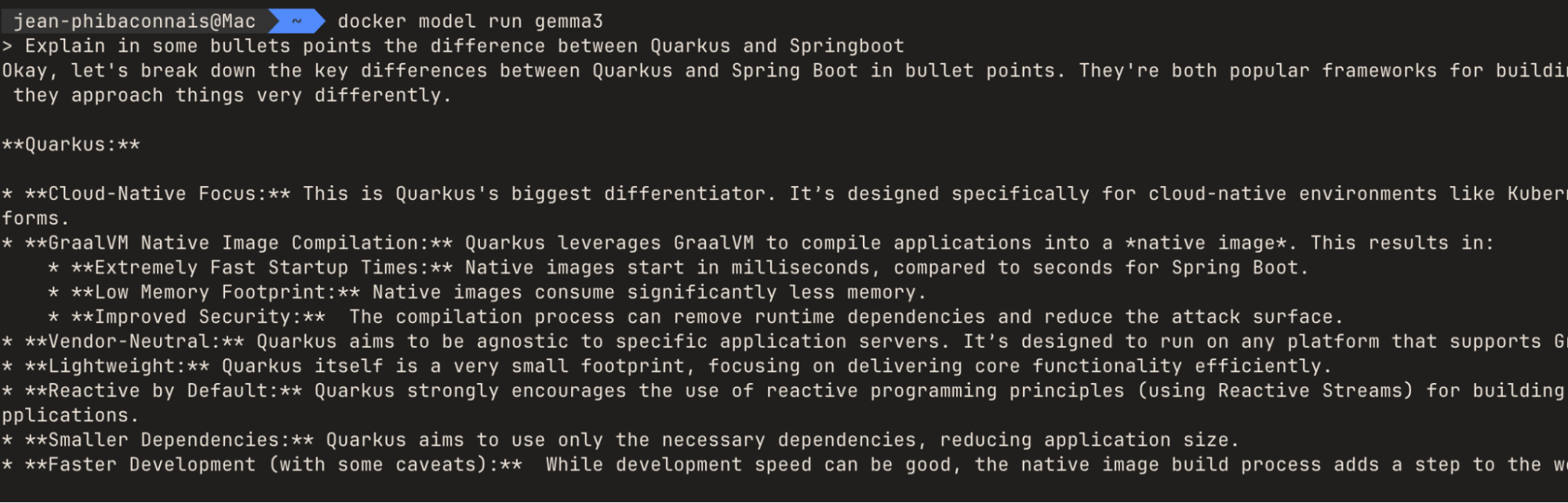
docker model run gemma3
Once started, the agent can respond to you as shown in this example:
🧩 The link between ADK / DMR
The langchain4j library will link the model specified in ADK and the model provided by DMR. This dependency must to be added:
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-open-ai</artifactId>
<version>1.1.0</version>
</dependency>
The code will be a little bit modified. Instead of calling the model with a string, we use an instance of the LangChain4j class, defined with an OpenAiChatModel instance.
OpenAiChatModel chatModel = OpenAiChatModel.builder()
.baseUrl(modelUrl)
.apiKey("not-needed-for-local")
.modelName(modelName)
.maxRetries(1)
.timeout(Duration.ofMinutes(2))
.build();
var adkModel = new LangChain4j(chatModel);
return LlmAgent.builder()
.name("Travel Agent")
.description("Travel expert using a local model")
.model(adkModel)
.build();
🙌 A Locally Available Agent
The agent is now plugged into a local model. The application can be started with the Maven command mvn compile exec:java -Dexec.mainClass=adk.agent.TravelAgent after starting your model with Docker Model Runner. For development, this is perfect.
Once the application was functional, I decided to set up a docker-compose.yml file to start the model and the application with a single command:
docker compose up -d --build && docker attach adk-app
💡To avoid repackaging the application every time, a cache is implemented in the Dockerfile.

TADA! 🥳
🤔 A “Local” Future?
This project was just an experimentation, but it gives some other questions. My primary use of AI is for development. Wouldn’t it be better to dedicate a locally deployed agent to this activity?
When I create agents planned to be deployed on the Cloud, perhaps a local model would be more than sufficient during the development phase? These questions have been answered by others who have tested this, but can it be implemented (and quickly) in a corporate context?
We can, of course, go even further by building our own custom model for our specific context, but that’s a topic for another day! 😁